
Meta Llama:关于开源生成式AI模型您需要了解的一切
与其他科技巨头一样,Meta也推出了自家的旗舰生成式AI模型——Llama。该模型的独特之处在于其“开源”特性:开发者可自由下载并使用(存在一定限制)。这与Anthropic的Claude、谷歌的Gemini、xAI的Grok以及OpenAI大部分ChatGPT模型形成鲜明对比——后者仅能通过API接口调用。
为提升开发者灵活性,Meta还与AWS、谷歌云、微软Azure等云服务商合作,推出云端托管版Llama。同时,公司通过《Llama开发指南》发布工具库与优化方案,助力开发者进行领域定制、效果评估及模型适配。随着Llama 3、Llama 4等新一代模型问世,功能已扩展至原生多模态支持与更广泛的云部署。
本文将全面解析Meta Llama的核心能力、版本差异及应用场景,并随官方更新持续补充最新动态。
Llama是什么?
Llama是一个模型系列,最新版本Llama 4于2025年4月发布,包含三款模型:
- Scout:170亿激活参数,1090亿总参数,上下文窗口达1000万token
- Maverick:170亿激活参数,4000亿总参数,上下文窗口为100万token
- Behemoth:尚未发布,预计配备2880亿激活参数与2万亿总参数
(注:在数据科学中,token指原始数据的细分单元,例如单词“fantastic”可拆分为“fan”“tas”“tic”三个音节。)
模型的上下文窗口指生成输出时参考的输入数据量。较长的上下文能避免模型“遗忘”近期内容或偏离主题,但可能削弱安全护栏效果,导致输出内容更易迎合对话语境,甚至引发用户认知偏差。
作为参考,Llama 4 Scout的1000万token上下文约等于80部普通小说的文本量,Maverick的100万token则相当于8部小说。
据Meta透露,所有Llama 4模型均基于海量未标注文本、图像及视频数据训练,具备“广泛的视觉理解能力”,并支持200种语言。
Llama 4 Scout与Maverick是Meta首批开源权重的原生多模态模型,采用“专家混合”架构以降低计算负载,提升训练推理效率。例如Scout集成16位专家,Maverick则拥有128位专家。Behemoth包含16位专家,被定位为小模型的“教师模型”。
Llama 4在Llama 3系列(含3.1与3.2版本)基础上演进,后者广泛用于指令调优与云端部署场景。
Llama能做什么?
与其他生成式AI模型类似,Llama可执行编程辅助、基础数学解答、文档摘要等任务,支持至少12种语言(阿拉伯语、英语、德语、法语、印地语、印尼语、意大利语、葡萄牙语、西班牙语、他加禄语、泰语、越南语)。其文本处理能力覆盖PDF、电子表格等大型文件分析,且Llama 4全系支持文本、图像及视频输入。
具体而言:Scout专为长流程工作与大规数据分析设计;Maverick作为通用模型,在推理能力与响应速度间取得平衡,适用于编程、聊天机器人及技术助手场景;Behemoth则面向前沿研究、模型蒸馏与STEM任务。
包括Llama 3.1在内的模型可配置调用第三方应用与API:通过Brave Search获取实时事件信息,借助Wolfram Alpha API处理数理查询,使用Python解释器验证代码。但需注意,这些工具需手动配置,非默认启用。
如何使用Llama?
若想直接体验对话功能,Llama已集成至Meta AI聊天机器人,覆盖Facebook Messenger、WhatsApp、Instagram、Oculus及Meta.ai平台,服务40个国家/地区。经微调的Llama版本在超200个国家/地区的Meta AI服务中运行。
Llama 4的Scout与Maverick模型可通过Llama.com及Hugging Face等合作平台获取,Behemoth仍在训练中。开发者可在主流云平台下载、使用或微调模型。Meta宣称拥有超25家合作托管方,包括英伟达、Databricks、Groq、戴尔、Snowflake等。虽然Meta不直接“销售”开源模型访问权,但通过与托管方分成协议获利。
部分合作方在Llama基础上开发了增强工具,例如支持模型调用专有数据、实现低延迟运行等功能。
需特别注意Llama的授权限制:月活用户超7亿的应用开发者需向Meta申请特殊许可,由公司酌情授权。
2025年5月,Meta启动“Llama for Startups”计划,为初创企业提供技术支持与潜在融资机会。
为确保模型安全使用,Meta配套推出以下工具:
- Llama Guard:内容审核框架
- CyberSecEval:网络安全风险评估套件
- Llama Firewall:构建安全AI系统的防护栏
- Code Shield:对大模型生成的不安全代码进行推理时过滤,支持7种编程语言
Llama Guard致力于检测输入/输出中的潜在违规内容,涉及犯罪活动、儿童剥削、版权侵犯、仇恨言论、自残及性虐待等范畴。但该工具并非万无一失——Meta早期准则曾允许聊天机器人与未成年人进行暧昧对话,部分记录显示对话最终转向性话题。开发者可自定义屏蔽内容类别,并应用于Llama支持的所有语言。
Prompt Guard专用于阻断针对模型的恶意攻击指令(如越狱攻击),Llama Firewall则防范提示词注入、不安全代码及危险工具交互等风险。Code Shield专注于降低不安全代码建议风险,提供安全命令执行环境。
CyberSecEval实为安全基准测试集,用于评估模型在“自动化社会工程”“规模化网络攻击”等领域对开发者及终端用户构成的潜在风险。
Llama的局限性
与所有生成式AI模型一样,Llama存在固有风险与局限。例如其最新模型虽具备多模态能力,但目前主要限于英语场景。
更宏观的挑战在于:Meta使用盗版电子书及文章数据集训练Llama模型。尽管联邦法官在一起作者集体诉讼中裁定“训练使用版权作品属于合理使用”,但若Llama输出版权内容片段且被商用,使用者可能面临侵权责任。
此外,Meta颇具争议地使用Instagram和Facebook的帖子、图片及标题训练AI,且未向用户提供便捷的退出机制。
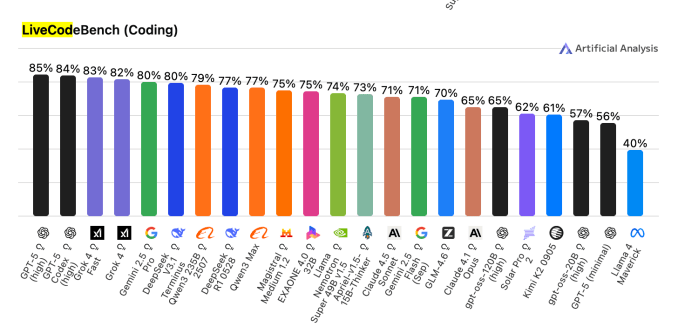
编程领域需格外谨慎:Llama生成代码的缺陷率可能高于同类模型。在LiveCodeBench(专注竞技编程问题的基准测试)中,Llama 4 Maverick得分仅40%,远低于OpenAI GPT-5高分版的85%与xAI Grok 4 Fast的83%。
务必谨记:任何AI生成代码都需经人类专家审核后方可投入应用。
最后,与其他AI模型相同,Llama仍会生成看似合理实则错误或误导的信息——无论是代码、法律建议还是与AI角色的情感对话。
本文最初发表于2024年9月8日,并随进展持续更新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...