
DeepSeek发布稀疏注意力模型使API成本减半
周一,深度求索(DeepSeek)的研究团队发布了名为V3.2-exp的全新实验模型。该模型专为长上下文场景设计,能显著降低推理成本。团队通过在Hugging Face平台发布公告,并在GitHub同步公开了相关学术论文。
核心技术:稀疏注意力机制
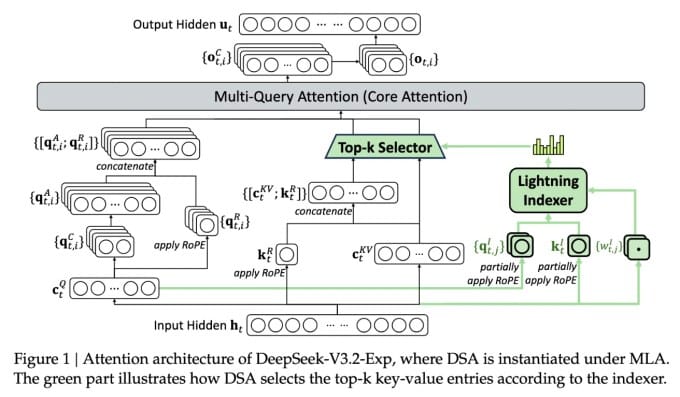
新模型最突出的特性是”深度求索稀疏注意力”系统。如图所示,该系统包含两大核心模块:首先,”闪电索引器”会对上下文窗口中的内容进行优先级排序;随后,”细粒度令牌选择系统”从优先段落中精准筛选特定令牌,将其载入有限的注意力窗口。通过这种协同工作机制,稀疏注意力模型能够在保持较低服务器负载的前提下,高效处理长文本内容。
性能突破与验证
在长上下文操作中,该系统展现出显著优势。深度求索的初步测试表明,简单API调用的成本最高可降低50%。虽然仍需更多测试来完善评估体系,但由于该模型采用开放权重并在Hugging Face免费提供,第三方机构很快就能对论文中的声明进行独立验证。
行业背景:推理成本优化竞赛
深度求索的新模型是近期推理成本攻坚领域的一系列突破之一。与训练成本不同,推理成本特指预训练AI模型运行时的服务器开销。该团队的研究重点在于提升基础Transformer架构的运行效率,事实证明这方面存在巨大的优化空间。
深度求索的独特发展路径
作为中国AI浪潮中的特立独行者,深度求索始终保持着独特的发展轨迹——尤其对于那些将AI竞争视为中美对决的观察者而言。今年初其发布的R1模型曾引发轰动,该模型主要采用强化学习训练,成本远低于美国同行。虽然R1未能如预期引发AI训练革命,且公司近期声量有所减弱,但这次发布的稀疏注意力技术仍可能为美国供应商提供降低推理成本的重要借鉴。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...